
当城市规模发展到一定程度之后,城市建设将会由外延式拓展逐渐让位于内涵式的更新、改造和保护。这意味着受城市土地资源的限制,新建房数量会逐步减少,而存量房的保有量将会越来越大,此时房地产市场的交易重心必然会从新房转移到二手房上来。本次试验通过对链家重庆二手房公开数据的统计分析,研究影响重庆二手房房价的影响,为二手房定价提供理论依据。
2017年7月,重庆二手住宅成交14125套,而2016年7月成交则是4407套,同比增长3倍多。重庆二手房市场正在蓬勃发展。研究二手房房价问题也正在情理之中。那么二手房房价的合理价格到底是多少呢?这个问题牵扯到很多因素:卧室数、客厅数、楼层高度、房屋朝向、装修状况、总面积、建造年份、房屋类型、有无电梯、周围有没有轻轨以及所在的位置。众多因素中,哪些重要?哪些不重要?能否将它们的相对重要性量化出来?如果能回答这个问题,我们就可以帮助自己为理想的二手住房明码标价。这是研究的主要目的。
目标网址:链家
一、数据抓取
数据由python的scrapy框架采集,并存入MySQL。项目源代码已经托管到Github:https://github.com/Gripex-lee/CQhouse_data。
主要的文件CQhouse.py内容如下:
parse为对第一页的解析方法detail_parse通过parse方法提取详细信息- 每一个
item为一条数据 - 通过
xpath得到数据
1 | import re |
通过改写pipelines.py将得到的数据存入MySQL,该文件内容如下(此处以本地数据库为例):
1 | import pymysql |
前提是已经在本地数据库建立了cqhouse数据库并在其中建立表house_data:
1 | create database cqhouse; |
二、R 语言的简单处理
从MySQL中导入数据
1 | library(RMySQL) |
mydata的前几行如下: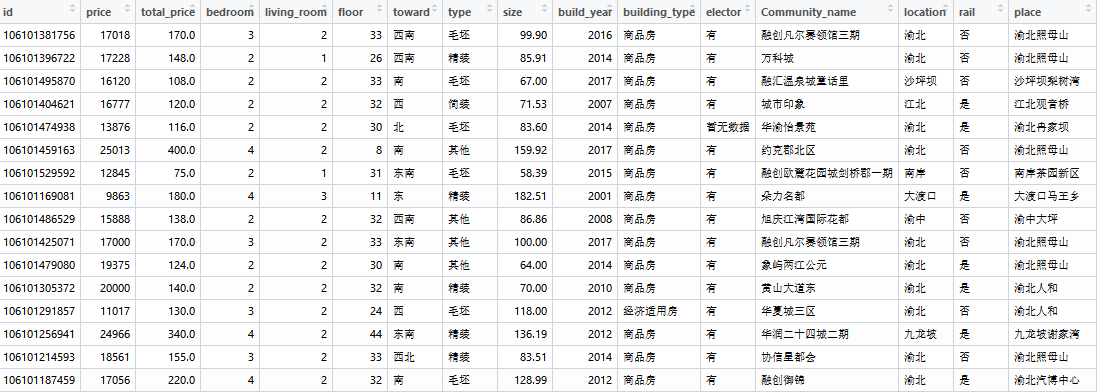
重命名变量+更改变量类型
由于存入数据库时定义的是字符变量,在这里对变量的类型进行更改,为了使用方便我们修改变量名。
1 | colnames(mydata) = c("id","price","total_price","bedroom","living_room","floor","toward", |
修改后的data如下,其中有几个变量含有缺失值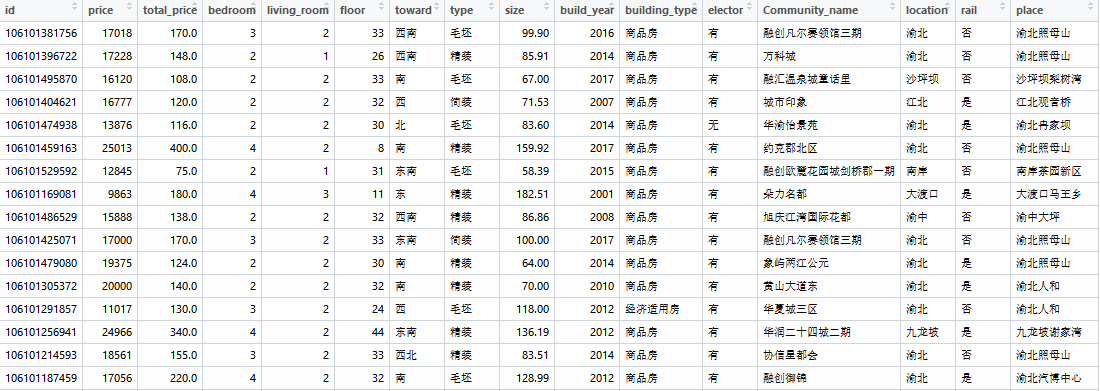
查看缺失值
1 | md.pattern(data) |
 从中可以了解到
从中可以了解到bulid_year缺失323个,elector缺失522个,type缺失967个。build_year和elector的缺失值较少,所以不打算删除这两个变量,考虑到变量type装修状况是一个能影响二手房价的重要因素,虽然其缺失值相对较多,但是我们仍不采用删除变量的操作。
下面用R进行缺失值处理:
- 对
build_year的缺失值用随机森林随机插补的方法(mice),不考虑跟建筑年份无关的变量:id,bedroom,living_room,elector(含缺失值),price(因变量),type(含缺失值); elector和type的缺失值采用最近邻插补KNN的方法补齐,因为相似的二手房可能在有无电梯和装修状况上有类似情况。
1 | mice_mod <- mice(data[, !names(data) %in% c('id','bedroom','living_room','elector','price','type')], |
 此时缺失值已经全部补齐。
此时缺失值已经全部补齐。
总共含2983条数据,每一个数据代表当时(2018-8-23)正在销售的二手房。因变量是房屋的销售价格(price),单位:元/平方米。除了因变量外,还考虑下面的解释变量,这些变量都能直接或间接地影响因变量(价格):
- 卧室数 (bedroom)、客厅数 (living_room)、面积 (size):该类指标的大小间接反映了房屋的大小和居住体验。
- 楼层高度 (floor):楼层越高空气流通越好,同时耗费的材料更多。
- 房屋朝向 (toward):不同的朝向对于采光、通风有较大的影响。
- 装修状况 (type):该指标刻画销售房屋是毛坯、简装还是精装房。显然,同一个房屋,精装的销售价格会显然高于毛坯和简装房。但是到底高多少还需要通过数据来得到结论。
- 建筑年份 (build_year):该指标对价格的影响显而易见,同种样式的房屋建筑年份越近说明越新。
- 房屋类型 (building_type):该指标刻画房屋是商品房还是经济适用房等,不同的类型对价格也有相应的影响。该指标有拆迁还建房、房改房、集资房、经济适用房、商品房5个值。
- 有无电梯 (elector):显然有电梯的相对会比没有电梯的价格高。该指标有是否两个值。
- 所在位置 (location):地理位置是一个重要的影响因素,我们这里主要研究在重庆,不同区的价格是否有显著的不同。
- 是否靠近轻轨 (rail):周围是否有轻轨决定了所在位置是否方便出行,如今轻轨是重庆市民的主要出行方式,因此这个指标是一个及其重要的指标,该指标有是和否两个值。
数值型变量(bedroom,living_room,floor,size,build_year)

从中可以得到类似下面的信息:
bedroom的最小值为1,最大值为9,中位数为3,均值2.791表明重庆二手房的卧室数量平均为2.791个;living_room最小值0表明有的二手房中没有客厅;floor:最高的楼层有58层,最低1层;size:房屋面积在20.39~574.08之间;build_year:二手房中建造年限最大的达到30年,同时也有今年刚建造的。
相关系数
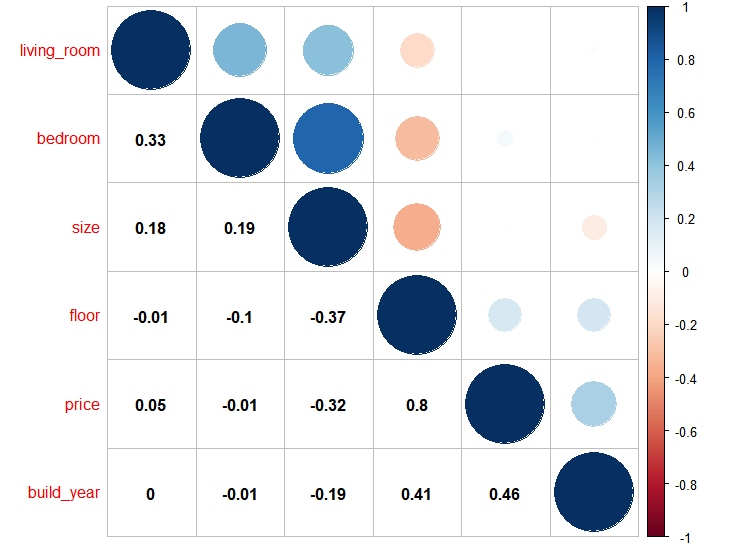
从相关系数的可视化中看到:
floor和price具有较强的相关性,相关系数达到0.8;size和price负相关;living_room和bedroom的相关性较弱。
分类型变量

从中可以得到类似下面的信息:
- 重庆二手房中
精装房较多,占比一半以上; - 样本中的房屋类型大多都是
商品房,分布不均匀。
price的直方图
1 | attach(data) |
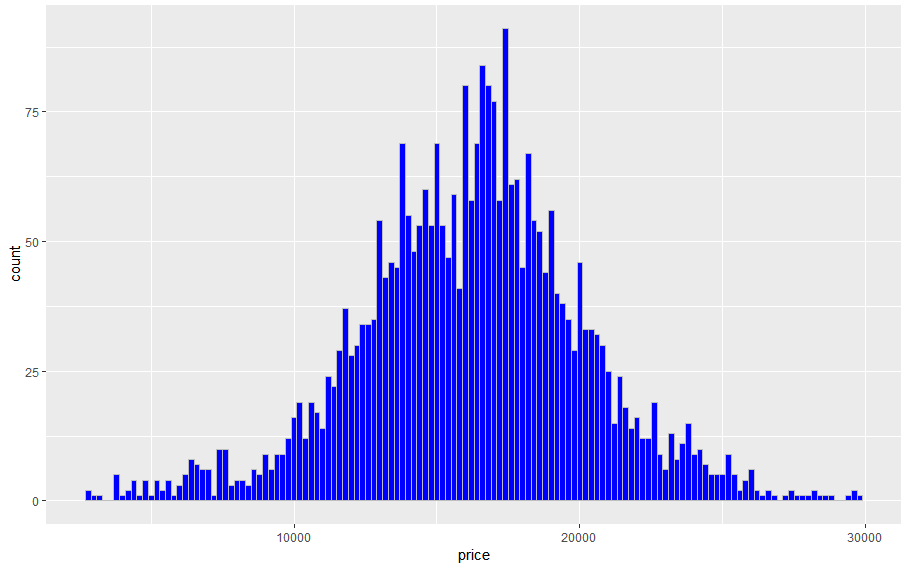
房屋价格大致服从正态分布,房价均值为16209.47元/平方米。
价格关于电梯在装修状况分类下的箱线图显示:
1 | ggplot(data,aes(x=elector,y=price))+ |

由图了解到:
- 不同
装修状况下二手房价没有明显差异; 有电梯的二手房的房价高于没有电梯的二手房房价。
二手房的地理分布
根据data中的place得到下图(由于place变量区分度不高,所以看到的点较少):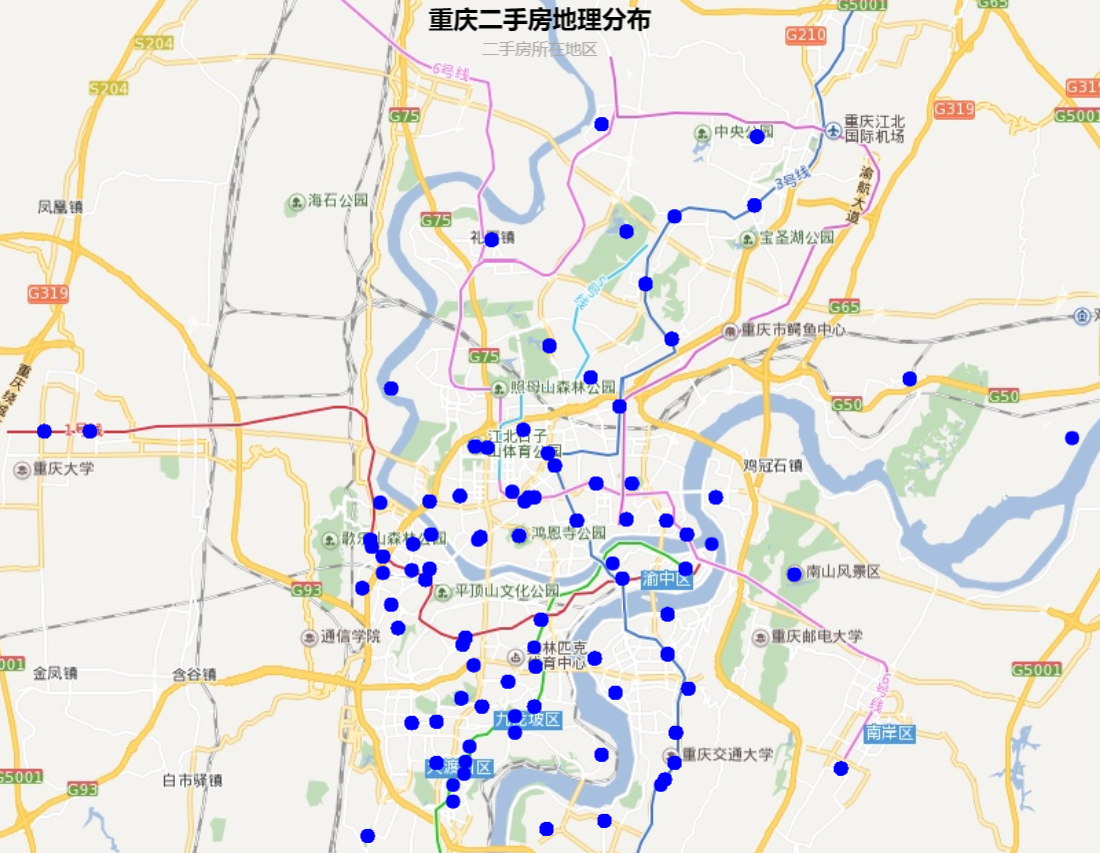
1 | library(REmap) |
由图了解到:
- 大部分的二手房地址在轨道线附近(也可能是由于重庆的轨道线覆盖较广导致);
- 江北、渝北、沙坪坝、渝中地区的房源较多;
由于房屋地理位置不是非常精确,图中无法反应过多信息,这一点可以在后期的改进中多花功夫。
价格关于地点location
1 | ggplot(data,aes(x=location,y=price))+geom_boxplot() |
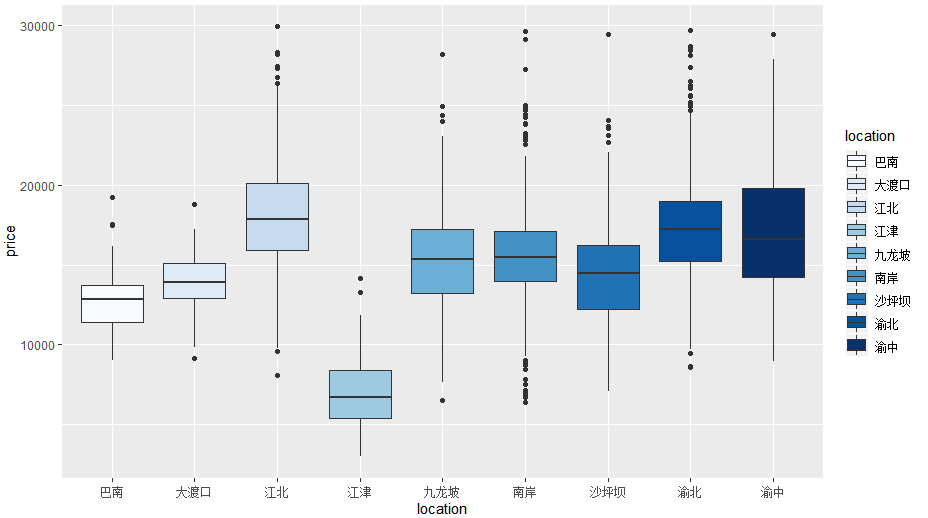
由图了解到:
- 位置的不同对房价有较大影响;
江北区的房价较均值最高,而江津最低。
关于朝向toward
1 | ggplot(data,aes(x=toward,y=price))+geom_boxplot() |

由箱线图知道不同的朝向在样本中表现为:没有较大差异,这似乎与普遍认知‘南北通透’较好有所相悖,或许是因为地域影响,山城的人民也许并不会因为房屋朝向而改变对这座城市的喜爱。
就所有变量建立模型
本次采用简单的线性模型来拟合二手房价和各影响因素的关系:1
2lm1=lm(price~bedroom+living_room+floor+type+size+build_year+building_type+elector+location+toward+rail,data)
summary(lm1)

模型的P值显著(说明至少有因素对二手房价有显著影响),拟合优度(该值越大说明拟合效果越好)为0.477。可能是由于变量对二手房价的影响实在太小或样本量分布不均所致,可以发现living_room,floor,building_type和房屋朝向都不显著。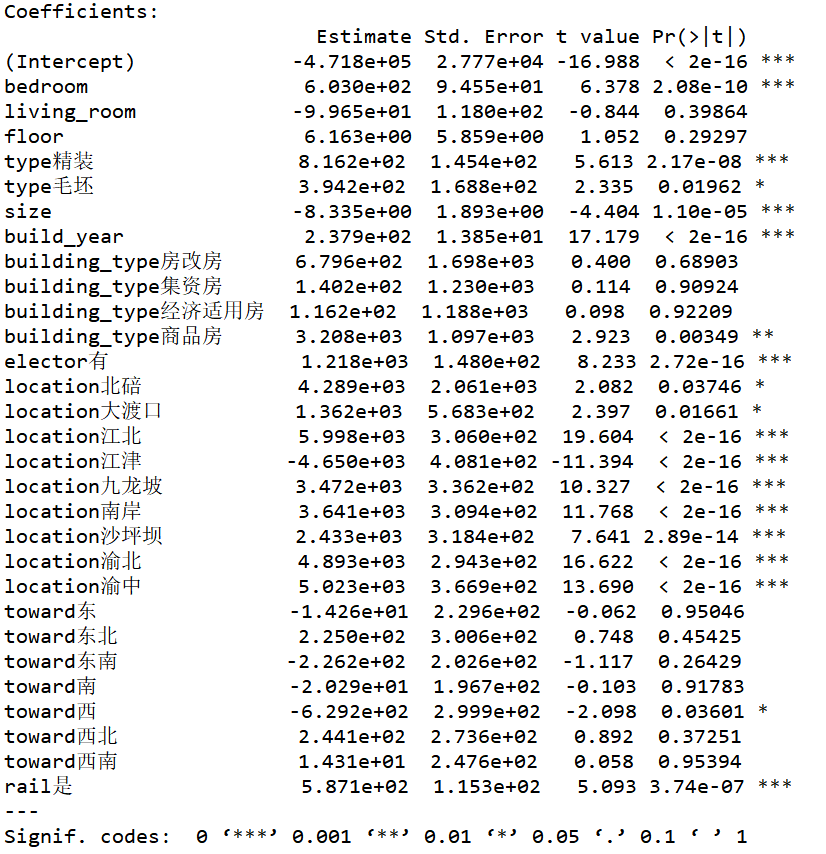
删除不显著变量后建立模型
1 | lm2=lm(price~bedroom+type+size+build_year+elector+location+rail,data) |
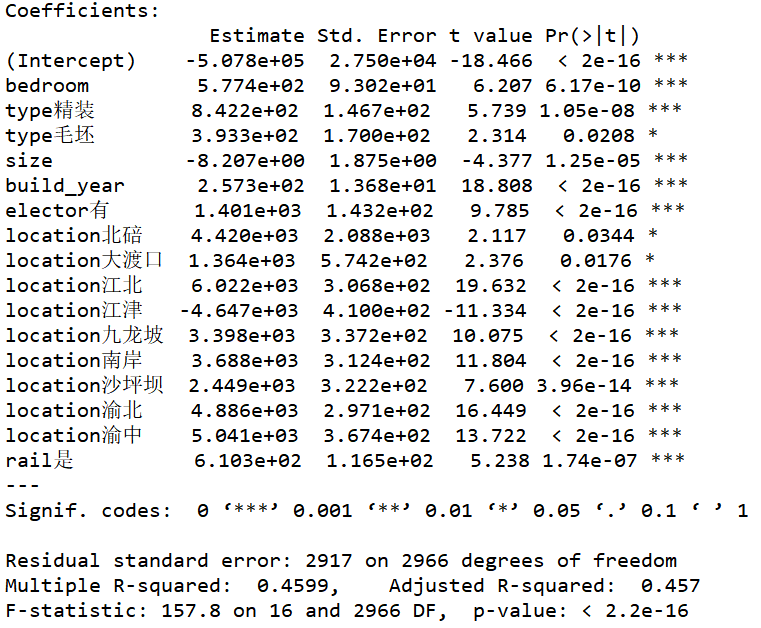
此时模型P值显著,拟合优度稍有降低,发现type毛坯、location北碚和location大渡口较显著外,其余变量都非常显著。说明模型建立成功。
从模型我们可以得到类似以下的结论:
- 在其他因素不变的情况下,
bedroom(卧室)的数量每增加一,房屋价格将上升577.4(元/平方米); - 在其他因素不变的情况下,
精装房要比简装房单价(元/平方米)平均高842.2(元/平方米),毛坯房要比简装房单价(元/平方米)平均高393.3(元/平方米),这似乎不能理解,原因可能是样本缺失值处理的不合理,也不乏毛坯房相比简装房会更方便按照自己的意愿装修的可能; - 在其他因素不变的情况下,二手房
总面积每增加1平方米,价格降低8.207(元/平方米); - 在其他因素不变的情况下,
建筑年份较1989年多一年,价格就多257.3(元/平方米); - 在其他因素不变的情况下,
有电梯的二手房比没有电梯的二手房的房价平均高1401(元/平方米); - 在其他因素不变的情况下,
北碚的二手房房价要比巴南(作为基准组)平均高4420(元/平方米),而江北的二手房价比北碚平均高6022-4420=1602(元/平方米),江津的二手房价比北碚平均低4420-(-4647)=9067(元/平方米); - 在其他因素不变的情况下,
在轻轨附近的二手房比不在轻轨附近的二手房的房价平均高610.3(元/平方米)。